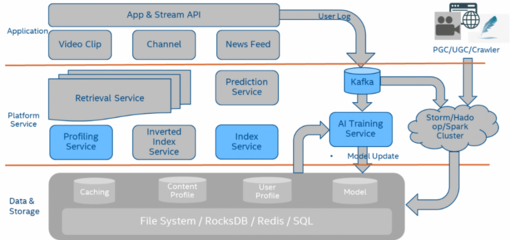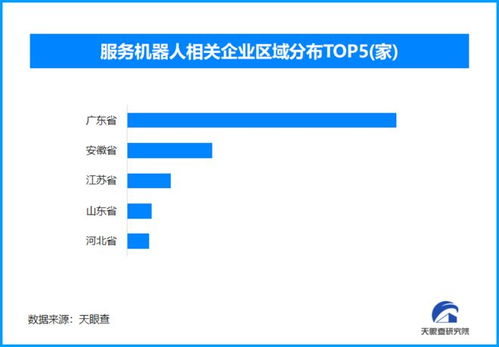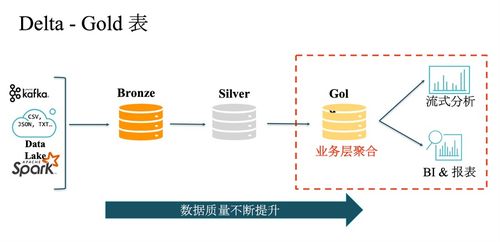
隨著大數(shù)據(jù)技術(shù)的演進(jìn),企業(yè)對(duì)于統(tǒng)一、高效且低成本的數(shù)據(jù)管理平臺(tái)的需求日益迫切。傳統(tǒng)的數(shù)據(jù)倉庫與數(shù)據(jù)湖架構(gòu)各有優(yōu)劣,但也暴露了各自的局限性。在此背景下,結(jié)合兩者優(yōu)勢(shì)的Lakehouse(湖倉一體)架構(gòu)應(yīng)運(yùn)而生,正成為現(xiàn)代數(shù)據(jù)架構(gòu)的新范式。本文將從架構(gòu)核心、數(shù)據(jù)處理模式及存儲(chǔ)服務(wù)特性三個(gè)維度,對(duì)Lakehouse進(jìn)行深度解析。
一、Lakehouse架構(gòu)解析:融合與統(tǒng)一的核心
Lakehouse的核心設(shè)計(jì)理念是在低成本、高可擴(kuò)展的云存儲(chǔ)(對(duì)象存儲(chǔ),如S3、ADLS、OSS)之上,構(gòu)建一個(gè)兼具數(shù)據(jù)湖的靈活性與數(shù)據(jù)倉庫的管理性能的統(tǒng)一數(shù)據(jù)平臺(tái)。其典型架構(gòu)分為三層:
- 統(tǒng)一的存儲(chǔ)層:基于云對(duì)象存儲(chǔ),以開放格式(如Parquet、ORC、Avro)存儲(chǔ)原始數(shù)據(jù)、清洗后的數(shù)據(jù)以及模型數(shù)據(jù)。這解決了數(shù)據(jù)孤島問題,實(shí)現(xiàn)了數(shù)據(jù)的單一副本存儲(chǔ),并顯著降低了存儲(chǔ)成本。
- 智能的管理與服務(wù)層:這是Lakehouse與傳統(tǒng)數(shù)據(jù)湖的關(guān)鍵區(qū)別。該層通過元數(shù)據(jù)管理、事務(wù)支持(ACID)、數(shù)據(jù)版本控制、數(shù)據(jù)治理(如數(shù)據(jù)血緣、訪問控制)以及索引與緩存等能力,為上層數(shù)據(jù)提供了類似數(shù)據(jù)倉庫的可靠性、一致性和高性能查詢基礎(chǔ)。典型的實(shí)現(xiàn)如Delta Lake、Apache Iceberg和Apache Hudi。
- 多樣化的計(jì)算與消費(fèi)層:Lakehouse支持多種計(jì)算引擎(如Spark、Flink、Presto/Trino)和BI工具(如Tableau、Power BI)直接訪問底層數(shù)據(jù),無需復(fù)雜的數(shù)據(jù)移動(dòng)和轉(zhuǎn)換。這實(shí)現(xiàn)了批處理、流處理、數(shù)據(jù)科學(xué)與機(jī)器學(xué)習(xí)工作負(fù)載在同一數(shù)據(jù)源上的無縫運(yùn)行。
二、數(shù)據(jù)處理范式:批流一體與AI/ML就緒
在數(shù)據(jù)處理方面,Lakehouse架構(gòu)帶來了革命性的變化:
- 批流一體處理:得益于事務(wù)日志和表格式(如Delta Log),Lakehouse能夠?qū)?shí)時(shí)流式數(shù)據(jù)以小批量(micro-batch)或連續(xù)處理的方式,以事務(wù)性保證寫入表中,使得同一張表可以同時(shí)支持歷史數(shù)據(jù)分析與實(shí)時(shí)流處理,簡(jiǎn)化了Lambda架構(gòu)的復(fù)雜性。
- 支持高級(jí)分析與機(jī)器學(xué)習(xí):數(shù)據(jù)科學(xué)家和機(jī)器學(xué)習(xí)工程師可以直接在存儲(chǔ)在Lakehouse中的原始數(shù)據(jù)或特征數(shù)據(jù)上開展工作,無需將數(shù)據(jù)導(dǎo)出到專用系統(tǒng)。這避免了數(shù)據(jù)不一致和重復(fù)存儲(chǔ),加速了從數(shù)據(jù)到洞察、再到模型部署的端到端流程。
- 模式演進(jìn)與數(shù)據(jù)質(zhì)量:通過Schema-on-Write與Schema-on-Read的靈活結(jié)合,以及內(nèi)置的數(shù)據(jù)質(zhì)量約束(如NOT NULL),Lakehouse在保持?jǐn)?shù)據(jù)湖靈活性的提升了數(shù)據(jù)的可靠性與可管理性。
三、存儲(chǔ)服務(wù)特性:低成本、開放與高性能
Lakehouse的存儲(chǔ)服務(wù)特性是其競(jìng)爭(zhēng)力的基石:
- 成本效益:核心存儲(chǔ)采用云對(duì)象存儲(chǔ),其成本遠(yuǎn)低于傳統(tǒng)塊存儲(chǔ)或數(shù)據(jù)倉庫的專用存儲(chǔ),且具備近乎無限的擴(kuò)展能力。
- 開放性與免鎖定:使用Parquet等開放列式格式存儲(chǔ),意味著數(shù)據(jù)所有權(quán)完全屬于用戶,不會(huì)被任何單一廠商的計(jì)算引擎或服務(wù)鎖定,促進(jìn)了生態(tài)的開放與互操作性。
- 性能優(yōu)化:雖然對(duì)象存儲(chǔ)的延遲較高,但Lakehouse通過多層技術(shù)彌補(bǔ):
- 元數(shù)據(jù)層優(yōu)化:高效的管理層將小文件合并、建立索引、維護(hù)統(tǒng)計(jì)信息,使查詢引擎能快速定位數(shù)據(jù)。
- 緩存與加速:支持在計(jì)算節(jié)點(diǎn)內(nèi)存或SSD上進(jìn)行數(shù)據(jù)緩存(如Delta Cache),并對(duì)熱點(diǎn)數(shù)據(jù)進(jìn)行智能分層,將熱數(shù)據(jù)緩存在高性能介質(zhì)上。
- 向量化執(zhí)行:現(xiàn)代查詢引擎能夠直接讀取列式格式,并利用SIMD指令進(jìn)行向量化計(jì)算,極大提升分析查詢速度。
- 企業(yè)級(jí)治理與安全:在統(tǒng)一的存儲(chǔ)基礎(chǔ)上,實(shí)現(xiàn)了細(xì)粒度的訪問控制、數(shù)據(jù)加密(靜態(tài)和傳輸中)、審計(jì)日志和合規(guī)性支持,滿足了企業(yè)級(jí)數(shù)據(jù)管理的嚴(yán)格要求。
與展望
Lakehouse架構(gòu)并非要完全取代數(shù)據(jù)倉庫或數(shù)據(jù)湖,而是旨在提供一個(gè)融合的統(tǒng)一平臺(tái),以應(yīng)對(duì)日益復(fù)雜的數(shù)據(jù)應(yīng)用場(chǎng)景。它降低了架構(gòu)復(fù)雜性、總擁有成本(TCO),并加速了數(shù)據(jù)價(jià)值變現(xiàn)的流程。隨著底層表格式標(biāo)準(zhǔn)的進(jìn)一步統(tǒng)一、查詢性能的持續(xù)優(yōu)化以及與云原生服務(wù)(如無服務(wù)器計(jì)算)的更深度集成,Lakehouse有望成為企業(yè)構(gòu)建現(xiàn)代化數(shù)據(jù)棧的首選架構(gòu)。其實(shí)施成功的關(guān)鍵在于,企業(yè)需要結(jié)合自身業(yè)務(wù)需求,審慎選擇技術(shù)組件,并建立與之匹配的數(shù)據(jù)治理與文化。